- Get link
- X
- Other Apps

Introduction
Artificial Intelligence (AI) is no longer a futuristic concept; It’s a part of our daily lives. From recommending what movie to watch next to enabling autonomous vehicles, AI has revolutionized the way we interact with technology. Yet, behind every smart algorithm lies a world of mathematics. Understanding the math behind AI is not just a theoretical exercise, it’s the foundation of building efficient, accurate, and interpretable machine learning models.
Whether you are a student, professional, or tech enthusiast, mastering these concepts gives you an edge in designing models that perform well and make meaningful predictions. ICT Skills AI and ML Courses train all AI Basic to Advance Concepts. Our this blog explores the essential math concepts that underpin AI, breaking them down in a human-friendly way, while providing real-world examples and practical insights.
Introduction
Math is often seen as abstract and intimidating, but in AI, it is the language through which machines understand the world. Every machine learning model, from a simple regression to a complex neural network, relies on mathematical principles to process data, identify patterns, and make predictions.
Consider a recommendation engine like the one used by Netflix. Behind the scenes, it uses matrices to represent user preferences, probability distributions to predict future behavior, and optimization techniques to refine recommendations. Without mathematics, these processes would be impossible.
By understanding the math behind AI, you not only improve your model-building skills but also gain the ability to troubleshoot and innovate. Instead of treating machine learning as a black box, you become a problem-solver who can design smarter, more efficient algorithms.
1. Why Math Matters in AI
Math is often seen as abstract and intimidating, but in AI, it is the language through which machines understand the world. Every machine learning model, from a simple regression to a complex neural network, relies on mathematical principles to process data, identify patterns, and make predictions.
Consider a recommendation engine like the one used by Netflix. Behind the scenes, it uses matrices to represent user preferences, probability distributions to predict future behavior, and optimization techniques to refine recommendations. Without mathematics, these processes would be impossible.
By understanding the math behind AI, you not only improve your model-building skills but also gain the ability to troubleshoot and innovate. Instead of treating machine learning as a black box, you become a problem-solver who can design smarter, more efficient algorithms.
2. Linear Algebra: The Language of Machine Learning
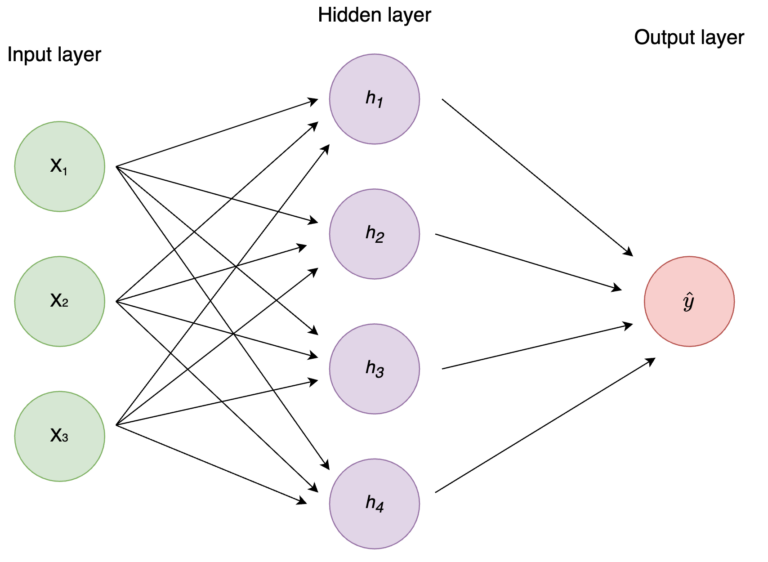
Linear algebra forms the backbone of many AI algorithms. At its core, linear algebra deals with vectors, matrices, and tensors—mathematical structures that organize data and facilitate computations.
Vectors and Matrices in AI
Vectors are essentially lists of numbers that can represent anything from an image pixel intensity to a feature of a dataset. Matrices, meanwhile, are two-dimensional arrays of numbers that store data efficiently and allow mathematical operations to be performed in bulk.
For example, in neural networks, input data is represented as a vector, which is multiplied by a weight matrix to generate output predictions. This operation is repeated across layers, allowing the model to learn complex patterns.
Tensors
A tensor is a generalization of vectors and matrices to higher dimensions. AI frameworks like TensorFlow and PyTorch rely heavily on tensors for processing large-scale data efficiently. Tensors allow models to handle images, videos, and even sequences of text in natural language processing tasks.
Why It Matters
Understanding linear algebra helps you:
- Represent data efficiently.
- Implement neural networks and other machine learning algorithms.
- Optimize computations for faster training.
Real-World Example:
When Google Translate converts text from English to Spanish, it represents each word as a vector in a high-dimensional space. Linear algebra operations determine how these vectors relate, enabling accurate translations.
3. Calculus: Optimization and Learning
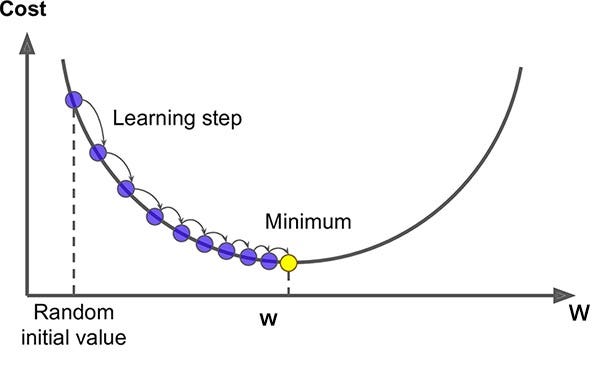
Calculus is the branch of mathematics that deals with change. In AI, calculus is fundamental for optimization—the process of minimizing errors in predictions.
Gradient Descent
Gradient descent is an algorithm used to find the minimum of a function. In machine learning, it helps minimize the loss function—the measure of how wrong a model’s predictions are.
Imagine you are standing on a hill (the loss function) and want to reach the lowest point (minimum error). Calculus tells you the slope of the hill (derivative), and gradient descent guides you downhill step by step.
Partial Derivatives
Most machine learning models depend on multiple variables. Partial derivatives allow us to understand how changing one variable affects the overall output, which is crucial in updating weights in a neural network.
Back-propagation
Back-propagation combines calculus with linear algebra to adjust weights in a neural network layer by layer. By computing derivatives of the loss function with respect to each weight, the network learns how to improve predictions iteratively.
Why It Matters:
Without calculus, machine learning models would not learn efficiently, and optimization would be nearly impossible.
4. Probability & Statistics: Decision-Making in AI
AI is all about making predictions under uncertainty, which is where probability and statistics come into play. These concepts help machines make informed decisions based on data.
Bayesian Models
Bayesian probability provides a framework for updating beliefs as new data arrives. For instance, spam filters use Bayesian reasoning to update the probability that an email is spam based on certain words or patterns.
Distributions
Probability distributions like Gaussian (normal) distributions model how data points are spread. Understanding distributions allows AI models to detect anomalies, classify data, and predict outcomes.
Correlation and Covariance
These statistical measures indicate relationships between variables. For example, understanding how temperature affects electricity usage can help AI systems optimize power distribution.
Real-World Example:
Fraud detection systems in banking use probability models to predict whether a transaction is legitimate. They calculate likelihoods based on patterns of historical data, allowing AI to flag unusual activity efficiently.
5. Linear & Logistic Regression: The Math Explained
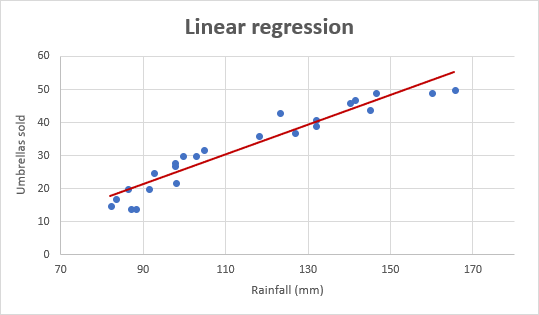
Regression techniques are the simplest yet most powerful tools in machine learning. They rely heavily on linear algebra, calculus, and statistics.
Linear Regression
Linear regression predicts a continuous outcome by fitting a line to data points. The formula is simple:
y = mx + b,
where m is the slope (weight) and b is the intercept (bias). Calculus helps find the values of m and b that minimize the error between predicted and actual outcomes.
Logistic Regression
When predicting categories (yes/no, spam/not spam), logistic regression is used. It converts a linear combination of inputs into probabilities using a logistic function. The model still relies on derivatives and optimization to minimize error.
Why It Matters:
Understanding these regression techniques builds intuition for more complex algorithms like neural networks.
6. Neural Networks: Putting It All Together
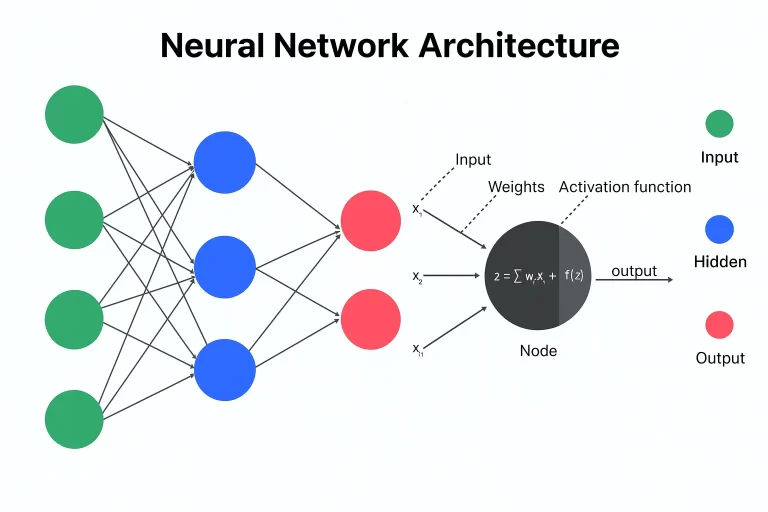
Neural networks are inspired by the human brain. They combine linear algebra (weights and activations), calculus (gradient descent), and probability (activation functions) to model complex relationships.
How It Works
- Inputs (vectors) are multiplied by weights (matrices).
- Bias is added, and an activation function introduces non-linearity.
- The output is compared to actual results using a loss function.
- Backpropagation updates the weights to improve predictions.
Human Analogy
Think of a neural network as a series of decision-making layers. Each layer evaluates the input slightly differently, improving understanding with every pass. The math ensures each decision is optimized for accuracy.
Real-World Example:
Self-driving cars use neural networks to interpret sensor data. Linear algebra processes the input, calculus optimizes the learning, and probability handles uncertainty in predictions.
7. Real-World Applications of Math in AI
Mathematics doesn’t just power algorithms—it drives innovation across industries:
- Healthcare: Predicting patient outcomes using regression and probabilistic models.
- Finance: Fraud detection and credit scoring using statistical models.
- Retail: Recommendation engines leverage linear algebra and optimization techniques.
- Autonomous Vehicles: Neural networks process sensor data for real-time decisions.
- Natural Language Processing: AI assistants use probability and linear algebra to understand language.
By mastering the math behind AI, professionals can design models that are not only accurate but also interpretable and reliable.
Conclusion
The math behind AI is not just a set of formulas—it is the backbone of machine learning success. From linear algebra and calculus to probability and statistics, these concepts enable machines to learn, predict, and adapt. For learners and professionals, understanding these principles opens doors to innovation and career growth in AI and data science.
For those eager to deepen their knowledge, platforms like ICT Skills provide structured courses and practical insights, bridging the gap between theory and real-world application.
Mathematics may seem challenging, but in AI, it is the key to unlocking transformative possibilities. By mastering these concepts, you gain the tools to not only understand AI but to shape its future.